CUDA Tips: nvcc’s -code, -arch, -gencode
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...

Recently I was working on a project related to the operation fusion in Tensorflow. My previous posts have covered several topics, such as how to enable fusion in TF, what’s inside the CBR fusion. I found I encountered the topological sort (topo_sort) often but I realized that probably I didn’t fully understand it. Originally, my understanding of topo_sort came from some coding interview books, and I knew it was simply a DFS variant, but this didn’t answer my questions that always in the back of my mind. By checking the implementation of the topo_sort in TF, I think I found the answers. In this post, I am going to list my questions and by analyzing each of them, it might be able to shed some light on how a more robust topo_sort should be implemented.
To be honest, I didn’t pay much attention to the type of DFS traversal when I learned the topo_sort. For example, in the left graph of Figure 1, it seems a DFS pre-order traversal is sufficient to produce the correct topological order of 0, 1, 2, 3. However, the method is brittle and easy to lead to wrong results if we simply change the order of the nodes as in the middle graph of Figure 1. In this case, we would probably get 0, 1, 2, 3 if the nodes are still swept in numerical order. But maybe we can argue that the correct order 3, 0, 1, 2 can still be achieved if we always start from the root node (which has no fanin edges). Unfortunately, this is not true. For instance, in the right graph in Figure 1, the preorder traversal will always fail to work, no matter which node we start from.
Figure 1. DFS preorder vs. postorder traversal
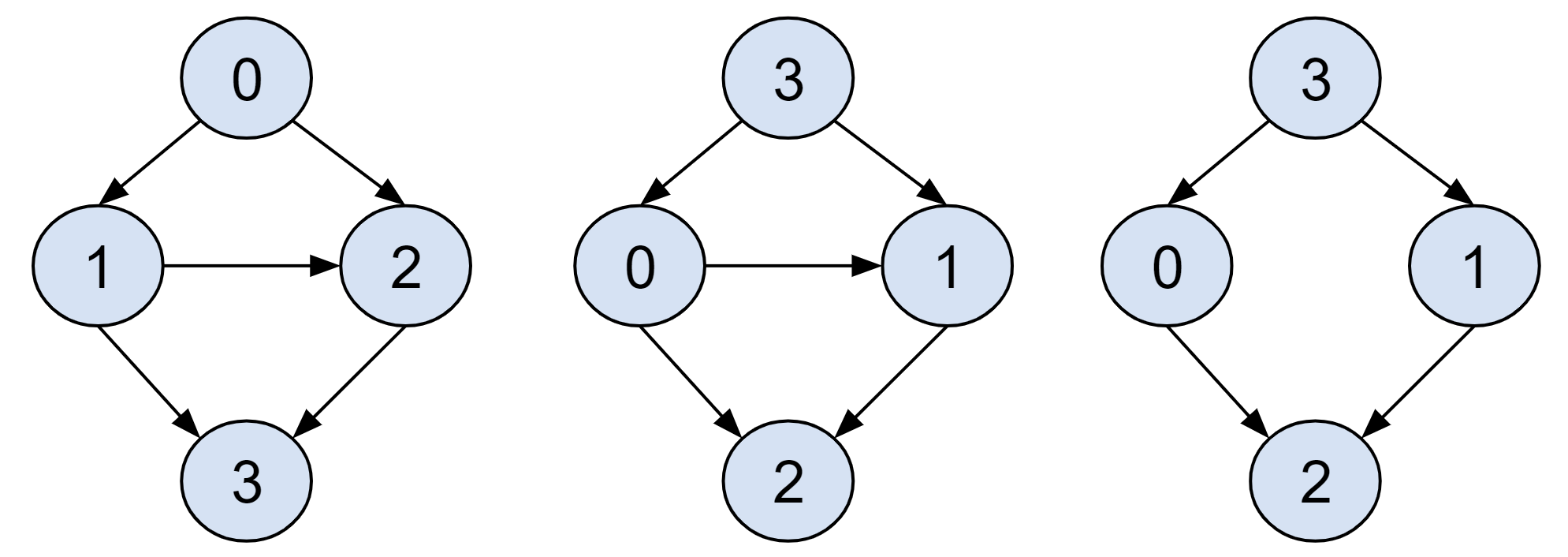
In fact, the DFS used in topo_sort is a reversed, postorder traversal. The postorder traversal can make sure that all the child nodes get processed before the current node. More importantly, it doesn’t matter if we start from the root node or not. For example, in the middle graph of Figure 1, the postorder traversal will always generate the order of 2, 1, 0, 3 regardless of the start node. After the traversal, we need one more step to reverse the order to get the correct result. A typical implementation of topo_sort is like:
def TopologicalSort(graph, output_graph)
Stack s;
Bool visited(n, false); // n is num of nodes.
For (each node i in graph)
If (not visited[i])
Helper(i, /*other params*/)
s.pop(all nodes) to output_graph // reverse
def Helper(i, s, visited, graph)
visited[i] = true
For (each child j of node i)
If not visited[j]
Helper(j, /*other params*/)
s.push(node i) // post_order traversal
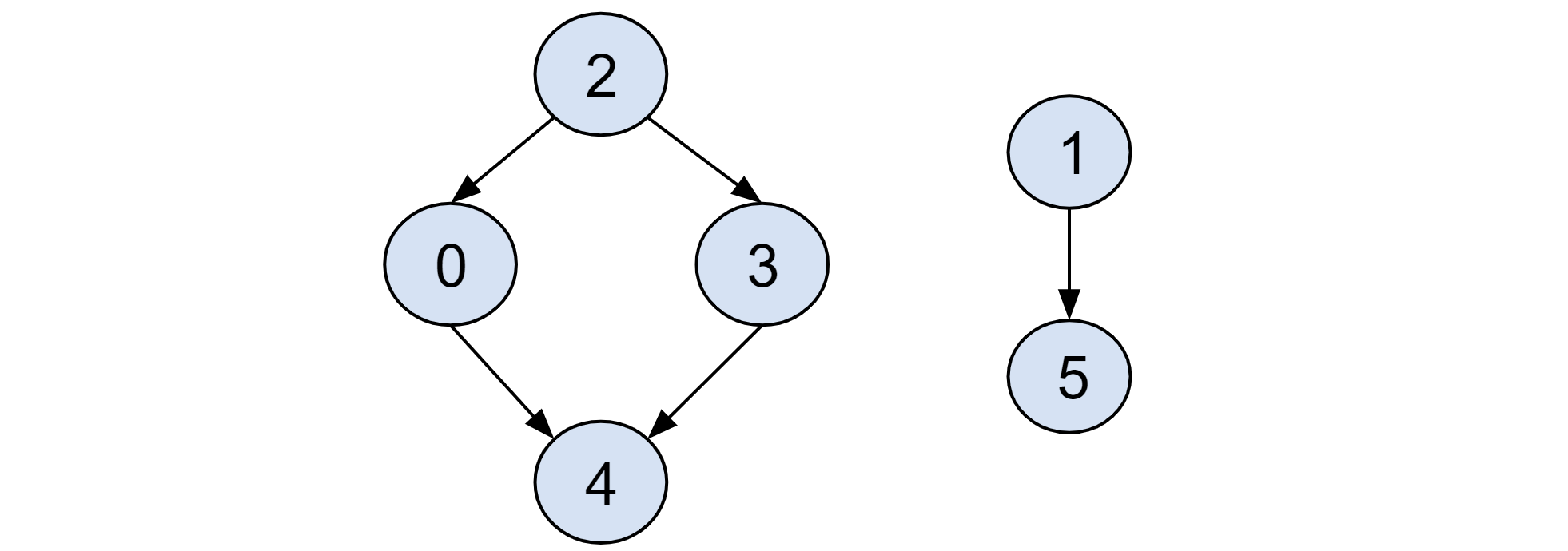
Suppose we have multiple graphs (like in Figure 2) to be processed by the topo_sort. The above topo_sort implementation could probably produce 2, 3, 1, 5, 0, 4. We can see that it is still a valid topological order; however, the nodes from the two graphs are interleaved in the results, which might be not desirable in many cases. One solution is to limit the start nodes to root nodes instead of any nodes during the sweep. With this simple change, we could obtain the order of 2, 0, 3, 4, 1, 5.
Figure 2. Mutiple graphs
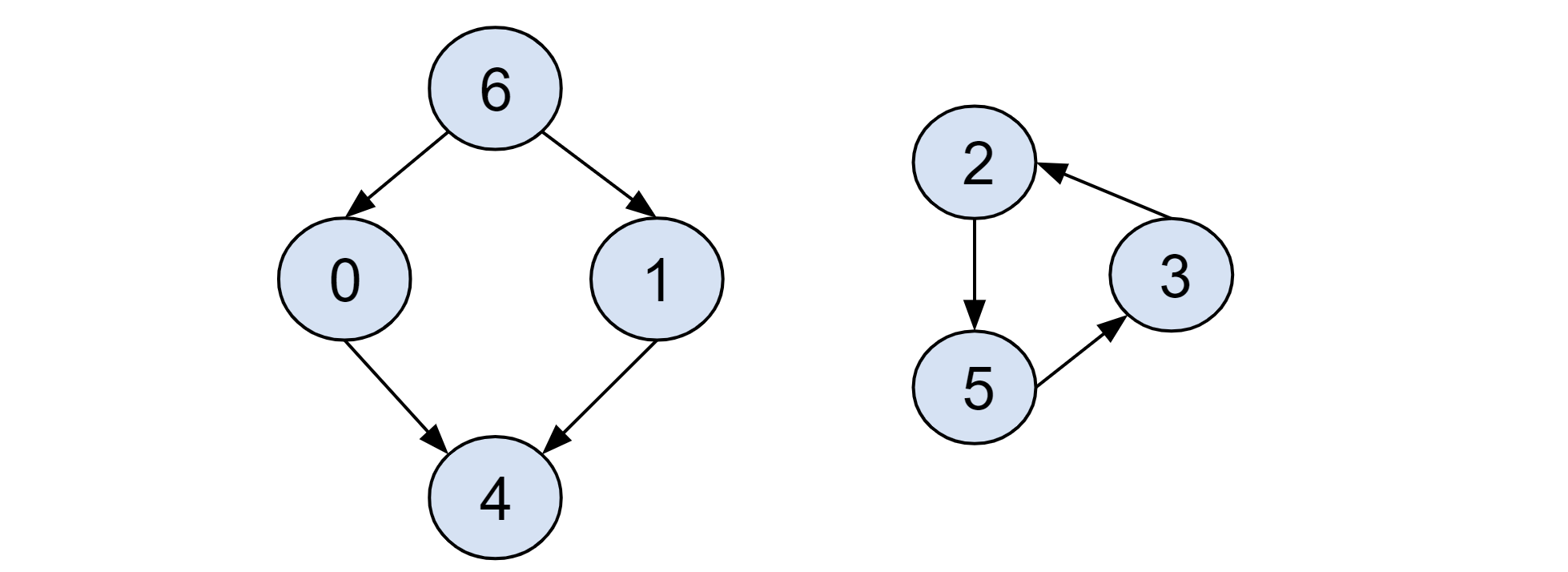
The cycles usually pose no problem for DFS when we have a proper array to keep track of whether the node has been processed or not. However, if we have a cycle graph, the “start-from-the-root-node” strategy will leave all the nodes in the cycle graph unprocessed. For example, Figure 3 has a cycle graph, meaning it has no root node to allow the sweep to begin with, and thus the result will be like 6, 1, 0, 4. To solve the issue, we can conduct a second round of sweep that starts from any unprocessed nodes. That way, the final order will contain all nodes: 2, 5, 3, 6, 0, 1, 4.
Figure 3. Cycle graph
The topo_sort used in TF can handle the above issues. Inspired by it, I gave a shot at implementing a toy topo_sort, which is non-recursive and features the ability to detect cycles.
#include<iostream>
#include<vector>
struct Node {
int idx;
std::vector<int> fanin;
std::vector<int> fanout;
Node() {}
Node(int i, std::vector<int> in, std::vector<int> out) :
idx(i), fanin(in), fanout(out) {}
};
enum TraversalState : uint7_t {PENDING, PROCESSING, PROCESSED};
enum StackState : uint8_t {ENTER, EXIT};
void helper(const std::vector<Node> &graph, int root_idx,
std::vector<TraversalState> &states,
std::vector<int> &order, int& order_idx,
bool &has_cycle) {
std::vector<std::pair<int, StackState>> s;
if (states[root_idx] == PENDING) {
s.push_back({root_idx, ENTER});
}
while(!s.empty()) {
auto cur_entry = s.back();
s.pop_back();
if (states[cur_entry.first] == PROCESSED) {
continue;
} else if (cur_entry.second == EXIT) {
states[cur_entry.first] = PROCESSED;
order[cur_entry.first] = order_idx--;
} else {
states[cur_entry.first] = PROCESSING;
s.push_back({cur_entry.first, EXIT});
auto &cur_node = graph[cur_entry.first];
for (int j = 0; j < cur_node.fanout.size(); j++) {
if (states[cur_node.fanout[j]] == PENDING) {
s.push_back({cur_node.fanout[j], ENTER});
} else if (states[cur_node.fanout[j]] == PROCESSING) {
has_cycle = true;
}
}
}
}
}
void topological_sort(const std::vector<Node> &graph,
std::vector<Node> &sorted,
bool &has_cycle) {
int node_num = graph.size();
std::vector<TraversalState> states(node_num, PENDING);
int order_idx = node_num - 1;
std::vector<int> order(node_num);
for(int i = 0; i < node_num; i++) {
if (graph[i].fanin.size() == 0) {
helper(graph, i, states, order, order_idx, has_cycle);
}
}
if (order_idx != -1) {
for(int i = 0; i < node_num; i++) {
helper(graph, i, states, order, order_idx, has_cycle);
}
}
for(int i = 0; i < node_num; i++) {
sorted[order[i]] = graph[i];
}
}
int main() {
std::vector<Node> graph;
graph.push_back(Node(0, {3}, {2}));
graph.push_back(Node(1, {3}, {2}));
graph.push_back(Node(2, {0, 1}, {}));
graph.push_back(Node(3, {}, {0, 1}));
std::vector<Node> sorted(graph.size());
bool has_cycle;
topological_sort(graph, sorted, has_cycle);
printf("The graph has cycle: %d\n", has_cycle);
printf("The topological order:\n");
for(int i = 0; i < graph.size(); i++) {
printf("%d, ", sorted[i].idx);
}
printf("\n");
}
Some highlights of the code:
states of PENDING,
PROCESSING, PROCESSED.s that can also keep track of the
node’s “stack status”: ENTER, EXIT.order to simply keep the ordered
index of each node.For each graph used in the post, the above code can correctly sort them and detect cycles as shown in the table:
| Graph | Topological Order | Has Cycle |
|---|---|---|
| Figure 1 left | 0, 1, 2, 3 | False |
| Figure 1 middle | 3, 0, 1, 2 | False |
| Figure 1 right | 3, 0, 1, 2 | False |
| Figure 2 | 2, 0, 3, 4, 1, 5 | False |
| Figure 3 | 2, 5, 3, 6, 0, 1, 4 | True |
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...
When training neural networks with the Keras API, we care about the data types and computation types since they are relevant to the convergence (numeric stab...
Introduction This post focuses on the GELU activation and showcases a debugging tool I created to visualize the TF op graphs. The Gaussian Error Linear Unit,...
Introduction My previous post, “Demystifying the Conv-Bias-ReLU Fusion”, has introduced a common fusion pattern in deep learning models. This post, on the ot...
Introduction Recently, I am working on a project regarding sparse tensors in Tensorflow. Sparse tensors are used to represent tensors with many zeros. To sav...
Introduction On my previous post Inside Normalizations of Tensorflow we discussed three common normalizations used in deep learning. They have in common a tw...
Introduction Recently I was working on a project related to the operation fusion in Tensorflow. My previous posts have covered several topics, such as how to...
Introduction My previous post, “Fused Operations in Tensorflow”, introduced the basics of operation fusion in deep learning by showing how to enable the grap...
Introduction The computations in deep learning models are usually represented by a graph. Typically, operations in the graph are executed one by one, and eac...
Introduction Horovod is an open source toolkit for distributed deep learning when the models’ size and data consumption are too large. Horovod exhibits many ...
Introduction Recurrent Neural Network (RNN) is widely used in AI applications of handwriting recognition, speech recognition, etc. It essentially consists of...
Introduction Recently I came across with optimizing the normalization layers in Tensorflow. Most online articles are talking about the mathematical definitio...