CUDA Tips: nvcc’s -code, -arch, -gencode
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...

People may feel confused by the options of -code, -arch, -gencode when
compiling their CUDA codes. Although the official guidance explains the
difference of them, users may still miss the important information embedded in
the document. This post summarizes the rules for using these options and their
compatibility with other options.
-arch : specifies which virtual compute architecture the PTX code should
be generated against. The valid format is like: -arch=compute_XY.-code: specifies which actual sm architecture the SASS code should be
generated against and be included in the binary. The valid format is like:
-code=sm_XY.-code: can also specify which PTX code should be included in the binary for
the forward compatibility. The valid format is like: -code=compute_XY.-gencode: combines both -arch and -code. The valid format is like:
-gencode=arch=compute_XY,code=sm_XY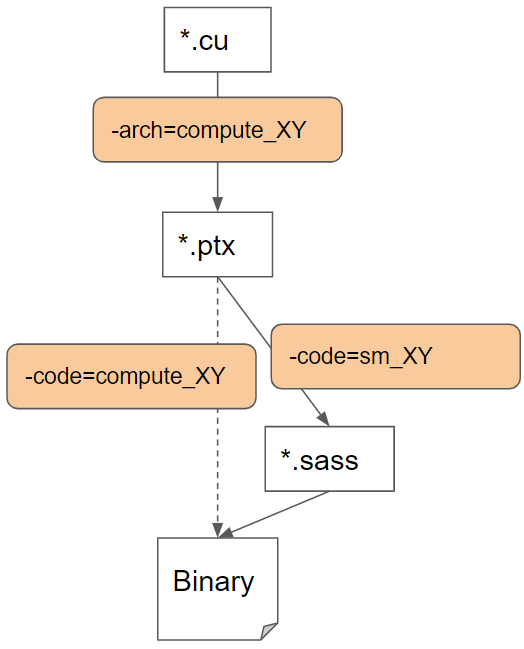
-arch=compute_*X is compatible with -code=sm_*Y when X≤Y. Examples:
-gencode arch=compute_100,code=sm_103 => OK-gencode arch=compute_103,code=sm_100 => nvcc fatal : Incompatible code generation-arch=compute_X* is compatible with -code=sm_Y* when X≤Y. Examples:
-gencode arch=compute_90,code=sm_100 => OK-gencode arch=compute_100,code=sm_90 => nvcc fatal : Incompatible code generationcuobjdump is a command can be used to examine or disassemble cubin/fatbin files or host executable.
cuobjdump <executable>
cuobjdump <executable> \
| grep '\(Fatbin\|arch =\)' \
| awk 'NR % 2 == 1 { o=$0 ; next } { print o " " $0 }' \
| sort | uniq -c
-code=sm_XY is only runnable on X.Y architecture.-code=compute_XY is runnable on X'.Y' architecture with JIT when X’.Y’≥XY.-arch=compute_80 -code=sm_80
-arch=compute_80 -code=compute_80,sm_80
-arch=compute_80 -code=compute_80,sm_80,sm_86
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_86,code=compute_86 \
-gencode=arch=compute_89,code=compute_89
-gencode=arch=compute_80,code=sm_80 \
-gencode=arch=compute_80,code=compute_80 \
-gencode=arch=compute_89,code=sm_89 \
-gencode=arch=compute_89,code=compute_89
CUDA 12.9 introduces Family-Specific Architecture features (link), complementing the Architecture-Specific features introduced with NVIDIA Hopper. These allow developers to optimize code using architecture-specific features with different levels of portability:
compute_100a includes all available instructions for the architecture but offers no forward compatibilitycompute_100f includes a subset of architecture-specific instructions that maintain compatibility within the same GPU family (same major version)compute_100 provides maximum forward compatibility across GPU generations but supports only the most basic instruction setThis relationship is illustrated in the Venn diagram below:
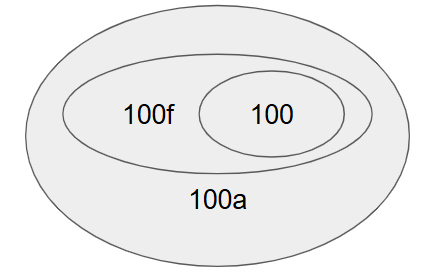
The following table shows the compatibility matrix between PTX and binary code generation options. While some combinations are included for completeness (like -gencode arch=compute_100,code=sm_100a) and may not be commonly used in practice, this overview helps illustrate the relationships between architecture and family-specific flags.
-arch=compute_X is compatible with -code=sm_X[a|f]*. Examples:
-gencode arch=compute_100,code=sm_100 => OK-gencode arch=compute_100,code=sm_100f => OK (A)-gencode arch=compute_100,code=sm_100a => OK-arch=compute_Xa is compatible with -code=sm_Xa. Examples:
-gencode arch=compute_100a,code=sm_100 => nvcc fatal : Incompatible code generation-gencode arch=compute_100a,code=sm_100f => nvcc fatal : Incompatible code generation-gencode arch=compute_100a,code=sm_100a => OK-arch=compute_Xf is compatible with -code=sm_X[a|f]*. Examples:
-gencode arch=compute_100f,code=sm_100 => OK (Equivalent with the above A)-gencode arch=compute_100f,code=sm_100f => OK (Equivalent with the above A)-gencode arch=compute_100f,code=sm_100a => OKIntroduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...
When training neural networks with the Keras API, we care about the data types and computation types since they are relevant to the convergence (numeric stab...
Introduction This post focuses on the GELU activation and showcases a debugging tool I created to visualize the TF op graphs. The Gaussian Error Linear Unit,...
Introduction My previous post, “Demystifying the Conv-Bias-ReLU Fusion”, has introduced a common fusion pattern in deep learning models. This post, on the ot...
Introduction Recently, I am working on a project regarding sparse tensors in Tensorflow. Sparse tensors are used to represent tensors with many zeros. To sav...
Introduction On my previous post Inside Normalizations of Tensorflow we discussed three common normalizations used in deep learning. They have in common a tw...
Introduction Recently I was working on a project related to the operation fusion in Tensorflow. My previous posts have covered several topics, such as how to...
Introduction My previous post, “Fused Operations in Tensorflow”, introduced the basics of operation fusion in deep learning by showing how to enable the grap...
Introduction The computations in deep learning models are usually represented by a graph. Typically, operations in the graph are executed one by one, and eac...
Introduction Horovod is an open source toolkit for distributed deep learning when the models’ size and data consumption are too large. Horovod exhibits many ...
Introduction Recurrent Neural Network (RNN) is widely used in AI applications of handwriting recognition, speech recognition, etc. It essentially consists of...
Introduction Recently I came across with optimizing the normalization layers in Tensorflow. Most online articles are talking about the mathematical definitio...