CUDA Tips: nvcc’s -code, -arch, -gencode
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...

My previous post, “Demystifying the Conv-Bias-ReLU Fusion”, has introduced a common fusion pattern in deep learning models. This post, on the other hand, will discuss another fusion pattern BatchNorm-Add-ReLU that also can be found in many models, such as ResNet50. Unlike the previous post, we will investigate the feasibility of the fusion for both forward and backprop stages.
As the convolution in the Conv-Bias-ReLU pattern, the BatchNorm is the most significant node in the BatchNorm-Add-ReLU pattern. Many articles have already demonstrated how the batch norm works and its backpropagation derived such as this one. For simplicity, here we only need to know what are the required inputs and expected outputs of the batch norm in its forward and backward passes respectively.
We assume the add op is a simple binary addition and thus we need two input x and z (also called the “side input”) and then output y. The backprop is to get dx and dz by using the backpropagated gradient input dy. As the BiasAdd shown in “this page”, the backprop is simply an “Identity” op to forward the dy and it doesn’t require any input from the forward pass. The equations are below:
| Add equations (forward) |
|---|
| y = x + z |
| Add equations (backward) |
|---|
| dx = ∂e/∂x = (∂e/∂y)(∂y/∂x) = dy |
| dz = ∂e/∂z = (∂e/∂y)(∂y/∂z) = dy |
The forward Relu is quite straightforward that we only need one input x and one output y. In contrast, to compute the dx, the backward Relu can either rely on x or y to pass the given backpropagated gradient dy. Mathematically, they are same but using y would be more “fusion-friendly”, since the x will become the “intermediate results” and be hard to access if the fusion is applied on BatchNorm-Add-ReLU.
| ReLU equations (forward) |
|---|
| y = 0, x ≤ 0 |
| y = x, x > 0 |
| ReLU equations (backward) |
|---|
| dx = 0, y ≤ 0 (or x ≤ 0) |
| dx = dy, y > 0 (or x > 0) |
Now, we can draw a figure to show how we can fuse these three operations. Based on the above analysis, the BatchNorm-Add-ReLU can be safely fused into one operation since the backward pass won’t use any intemediate results from the fused operation. The fused forward op will need input x, gamma/beta and side input z, and finally output y. For the backward pass, the ReluGrad and BatchNormGrad can also be fused together, which requires the backpropagated gradient dy and the output y, the input x and input gamma from the forward op to output the dx (input gradient), dγ/dβ (varialbel graidents), and dz (side input gradient).
Fig. Fused Ops for BatchNorm+Add+ReLU
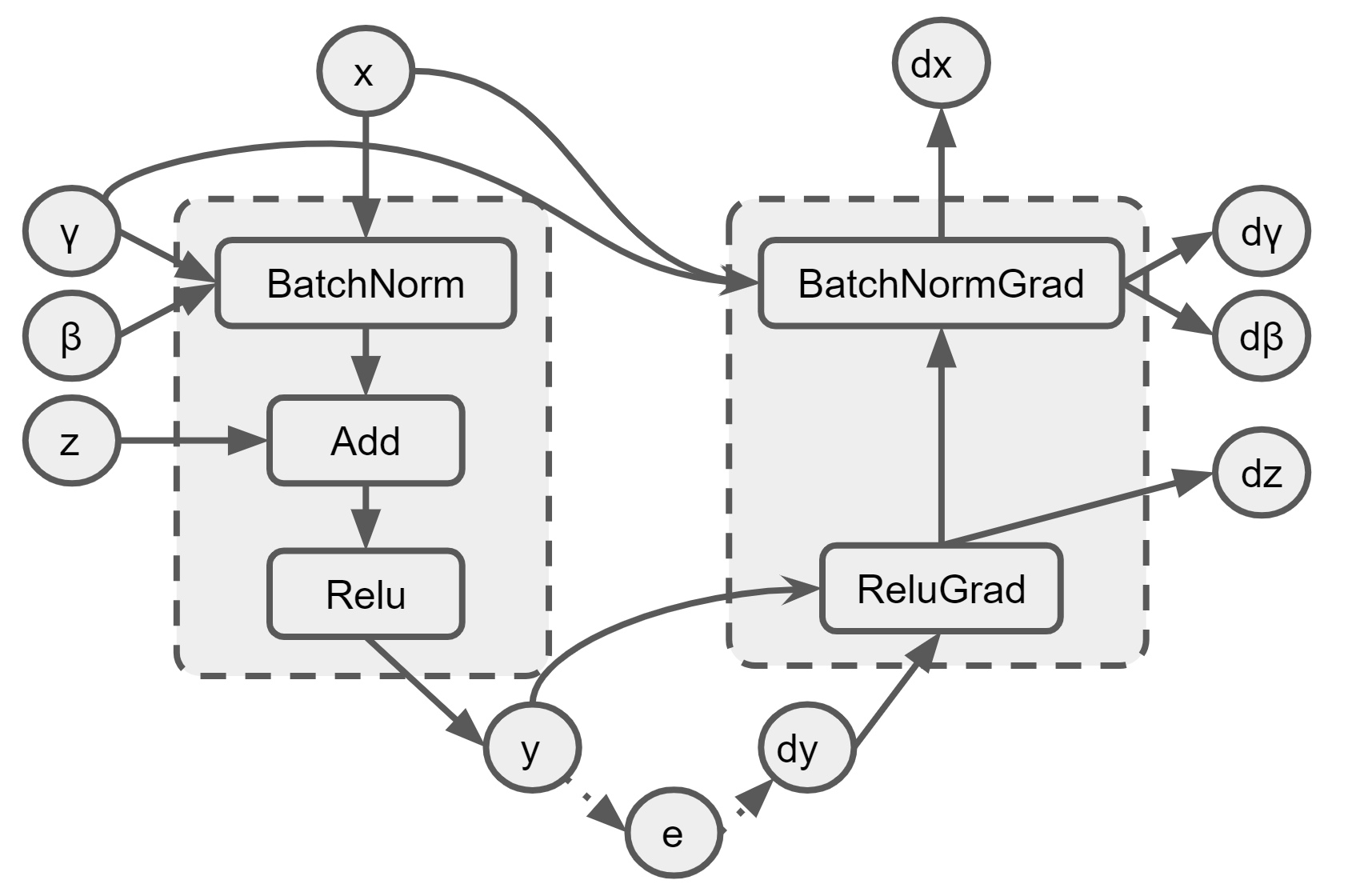
It is still worth to mention that this post focuses mainly on the scenario of training and discusses the fusion from the perspective of the data dependencies. In reality, the decision to fuse will be more complex than it seems.
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...
When training neural networks with the Keras API, we care about the data types and computation types since they are relevant to the convergence (numeric stab...
Introduction This post focuses on the GELU activation and showcases a debugging tool I created to visualize the TF op graphs. The Gaussian Error Linear Unit,...
Introduction My previous post, “Demystifying the Conv-Bias-ReLU Fusion”, has introduced a common fusion pattern in deep learning models. This post, on the ot...
Introduction Recently, I am working on a project regarding sparse tensors in Tensorflow. Sparse tensors are used to represent tensors with many zeros. To sav...
Introduction On my previous post Inside Normalizations of Tensorflow we discussed three common normalizations used in deep learning. They have in common a tw...
Introduction Recently I was working on a project related to the operation fusion in Tensorflow. My previous posts have covered several topics, such as how to...
Introduction My previous post, “Fused Operations in Tensorflow”, introduced the basics of operation fusion in deep learning by showing how to enable the grap...
Introduction The computations in deep learning models are usually represented by a graph. Typically, operations in the graph are executed one by one, and eac...
Introduction Horovod is an open source toolkit for distributed deep learning when the models’ size and data consumption are too large. Horovod exhibits many ...
Introduction Recurrent Neural Network (RNN) is widely used in AI applications of handwriting recognition, speech recognition, etc. It essentially consists of...
Introduction Recently I came across with optimizing the normalization layers in Tensorflow. Most online articles are talking about the mathematical definitio...