CUDA Tips: nvcc’s -code, -arch, -gencode
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...

The computations in deep learning models are usually represented by a graph. Typically, operations in the graph are executed one by one, and each time we need to perform memory read and write for their inputs and outputs respectively, which could lead to performance issues since the offchip memory access is oftentimes expensive. One way to improve that is to fuse the operations into a big one to reduce such memory footprint. Apparently, it is impractical to replace the whole graph into a monolithic operation; however, there are indeed many patterns (a subgraph showing how operations are wired together) that are quite common among various models, such as a convolution followed by a bias addition or a batch normalization followed by a relu activation. Tensorflow remaps these patterns onto more efficient implementations via the grappler remapper optimizer. This post will discuss how the fusion is actually triggered in TF with a focus on the convolution related patterns.
Below is the head part of the python script showing the configs we will use in the following tests. At the very beginning, we turn on the remapper’s logging to show whether the target patterns are successfuly fused.
import os
os.environ['TF_CPP_VMODULE'] = 'remapper=2'
import tensorflow as tf
import numpy as np
use_nhwc = True
N, H, W, C = 1, 2, 3, 3
k, r, s, c = 3, 2, 2, C
if use_nhwc:
x_format = 'NHWC'
x_format_keras = 'channels_last'
bias_format = 'N...C'
x_shape = (N, H, W, C)
channel_axis = -1
else:
x_format = 'NCHW'
x_format_keras = 'channels_first'
bias_format = 'NC...'
x_shape = (N, C, H, W)
channel_axis = 1
For a given graph, TF uses the grappler remapper to look for the supported patterns and if found, it replaces them with a single fused operation. To do this, there are roughly three steps in the overall process:
In fact, the remapper will also check the data types, layouts, underlying devices, etc. to determine if the replacement should be done or not.
The pattern of Conv2D + BiasAdd + Activation is so common among many CNN models that we would like a faster implementation. Here we use the TF low-level APIs to test the remapper. The low-level APIs allow us to write more flexible logic but require manually preparing the trainable parameters like filters and biases.
f_np = np.random.random([r, s, c, k]).astype(np.float32)
f = tf.Variable(f_np)
b_np = np.random.random([k]).astype(np.float32)
b = tf.Variable(b_np)
@tf.function
def fused_conv_bias_relu(x):
y = tf.nn.conv2d(x, f, strides=(1,1), padding='SAME',
data_format=x_format)
y = tf.nn.bias_add(y, b, data_format=bias_format)
y = tf.nn.relu(y)
return y
In the above script, we place the three operations of conv2d, bias_add, and
relu in the fused_conv_bias_relu and to trigger the remapper optimizer (or
other graph-based optimizations) we need to add the tf.function decorator.
Then, we can call the function with some fake input tensor.
inputs = tf.random.normal(x_shape)
outputs = fused_conv_bias_relu(inputs)
print(outputs)
The output contains the following log from the remapper, indicating the Conv2D + BiasAdd + Relu pattern is successfully detected and replaced.
I tensorflow/core/grappler/optimizers/remapper.cc:1114]
Fuse Conv2D with BiasAdd and Relu:
activation=Relu bias_add=BiasAdd contraction=Conv2D
To illustrate how the operations are replaced and how the edges are rewired, the
following two figures show differences between the original and optimized graphs
both of which are adapted from the Tensorboard. (By default, Tensorboard can
only show the unoptimized graph. To obtain the obtimized one, I use the
SerializeAsString() in the remapper and rebuild the TF to output the pb file.)
Fig 1. Original Graph
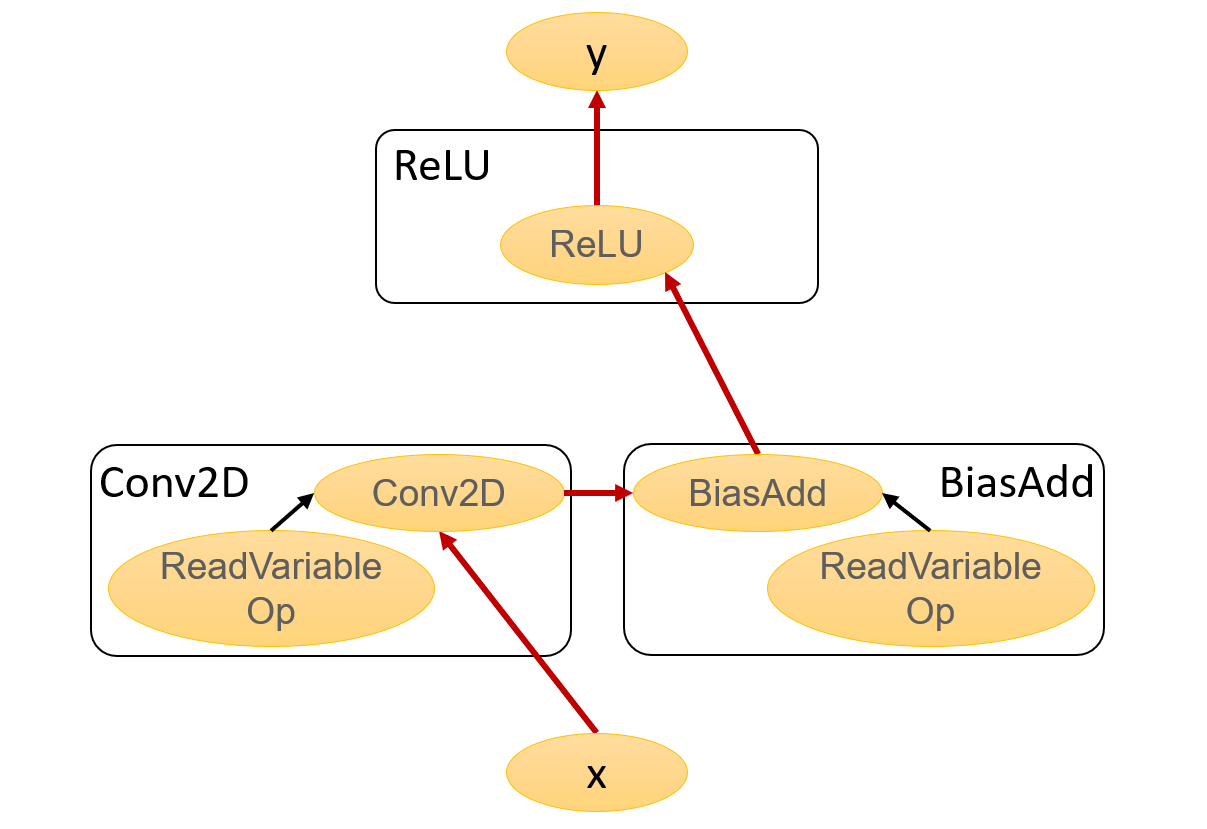
Fig 2. Optimized Graph
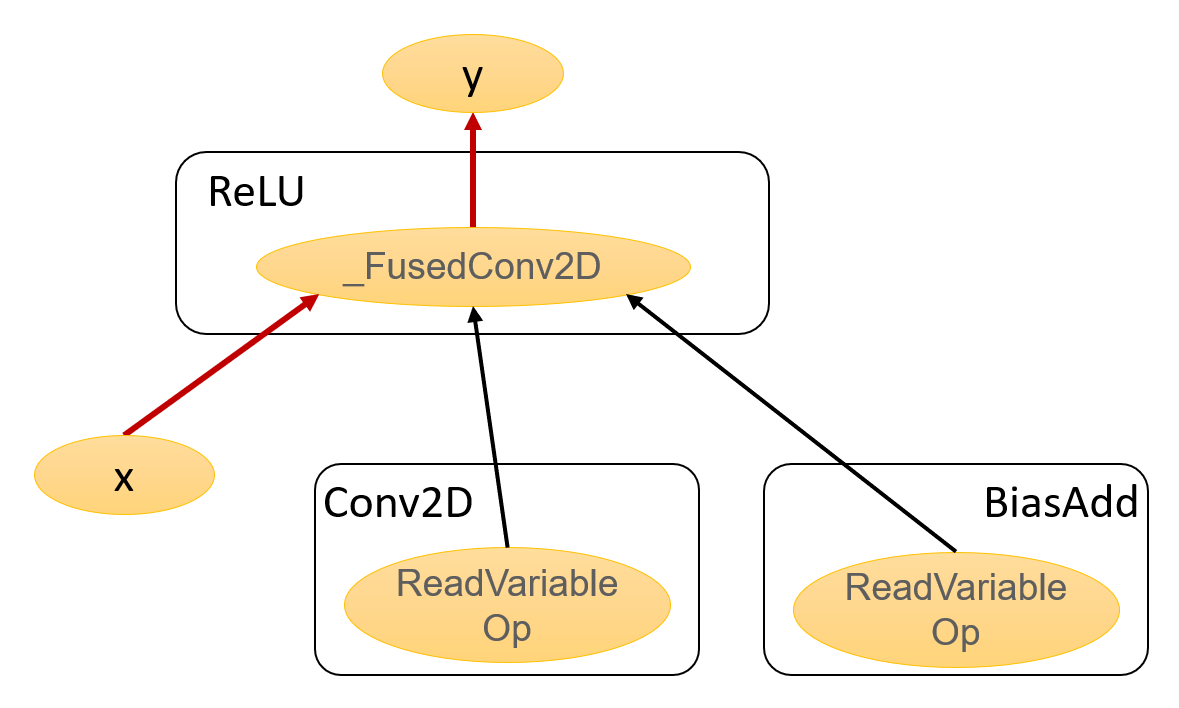
We can see that the fused operation _FusedConv2D is in place of the original
ReLU. More importantly, the red edges indicate the potential memory access and the
number of them are reduced from four to two, meaning we have saved some round
trips to the memory.
Using the high-level Keras API could be easier to reproduce the above test.
Note, by default, the Conv2D layer will apply a bias addition at the end.
conv2d = tf.keras.layers.Conv2D(
filters=k, kernel_size=(r, s), padding='same',
data_format=x_format_keras)
relu = tf.keras.layers.ReLU()
@tf.function
def fused_conv_bias_relu_keras(x):
y = conv2d(x)
y = relu(y)
return y
On GPUs, the _FusedConv2D backend will call
the fast cudnnConvolutionBiasActivationForward from CUDNN. However, it only supports
fp32 data type and ReLU activation (as of TF 2.4). The layout could be channels_first or
channels_last.
Other patterns are supported in the similar way. However, they might need
different criteria, including layouts or devices. For the pattern of Conv2D +
FusedBatchBorm + Activation, it is only supported on CPUs and the tensor layout
has to be NHWC (channels_last). The fusion can only be triggered in the
inference mode, since if it is in the training, the backward propagation will
need the output the of the Conv2D.
The following script is a test for this pattern and it is worth mentioning that
we shouldn’t use tf.nn.batch_normalization in place of fused_batch_norm
because it is essentially a collection of multiplication primitives rather than
the desired FusedBatchNorm.
mean = tf.random.normal((k,))
variance = tf.random.normal((k,))
offset_np = np.random.random([k]).astype(np.float32)
offset = tf.Variable(offset_np)
scale_np = np.random.random([k]).astype(np.float32)
scale = tf.Variable(scale_np)
@tf.function
def fused_conv_bn_relu(x):
with tf.device('/CPU:0'):
y = tf.nn.conv2d(x, f, strides=(1, 1), padding='SAME',
data_format=x_format)
y, _, _ = tf.compat.v1.nn.fused_batch_norm(
y, scale, offset, mean, variance,
data_format=x_format, is_training=False)
y = tf.nn.relu(y)
return y
Then we execute the function with use_nhwc = True and get the log that shows the
pattern is successfully recognized.
I tensorflow/core/grappler/optimizers/remapper.cc:1252]
Fuse Conv2D with BatchNorm and Relu:
activation=Relu batch_norm=FusedBatchNormV3 conv2d=Conv2D
Similerly, using the Keras API would be much easier and be sure to disable the bias add in Conv2D layer. By default, the BatchNormalization layer will use FusedBatchNorm operation if possible.
conv2d_no_bias = tf.keras.layers.Conv2D(
filters=k, kernel_size=(r, s), padding='same',
data_format=x_format_keras, use_bias=False)
batch_norm = tf.keras.layers.BatchNormalization(axis=channel_axis)
# CPU only requires use_nhwc = True
@tf.function
def fused_conv_bn_relu_keras(x):
with tf.device('/CPU:0'):
y = conv2d_no_bias(x)
y = batch_norm(y, training=False)
y = relu(y)
return y
This pattern is also only supported on CPUs. Therefore, we need to execute the
script with use_nhwc = True. Then, from the log, we can see the pattern is correctly
fused.
@tf.function
def fused_conv_squeeze_bias(x):
with tf.device('/CPU:0'):
y = tf.nn.conv2d(x, f, strides=[1,1], padding='VALID',
data_format=x_format)
y = tf.squeeze(y, axis=1 if use_nhwc else 2)
y = tf.nn.bias_add(y, b, data_format=bias_format)
return y
I tensorflow/core/grappler/optimizers/remapper.cc:1166]
Fuse Conv2D with Squeeze and BiasAdd:
bias_add=BiasAdd squeeze=Squeeze conv2d=Conv2D
The TF grappler remapper also supports other patterns with no convolution, such as FusedBatchNorm + SideInput + Activation. Besides, it is possible that more patterns would be added when they are classified to be common among deep learning models.
Introduction People may feel confused by the options of -code, -arch, -gencode when compiling their CUDA codes. Although the official guidance explains the d...
When training neural networks with the Keras API, we care about the data types and computation types since they are relevant to the convergence (numeric stab...
Introduction This post focuses on the GELU activation and showcases a debugging tool I created to visualize the TF op graphs. The Gaussian Error Linear Unit,...
Introduction My previous post, “Demystifying the Conv-Bias-ReLU Fusion”, has introduced a common fusion pattern in deep learning models. This post, on the ot...
Introduction Recently, I am working on a project regarding sparse tensors in Tensorflow. Sparse tensors are used to represent tensors with many zeros. To sav...
Introduction On my previous post Inside Normalizations of Tensorflow we discussed three common normalizations used in deep learning. They have in common a tw...
Introduction Recently I was working on a project related to the operation fusion in Tensorflow. My previous posts have covered several topics, such as how to...
Introduction My previous post, “Fused Operations in Tensorflow”, introduced the basics of operation fusion in deep learning by showing how to enable the grap...
Introduction The computations in deep learning models are usually represented by a graph. Typically, operations in the graph are executed one by one, and eac...
Introduction Horovod is an open source toolkit for distributed deep learning when the models’ size and data consumption are too large. Horovod exhibits many ...
Introduction Recurrent Neural Network (RNN) is widely used in AI applications of handwriting recognition, speech recognition, etc. It essentially consists of...
Introduction Recently I came across with optimizing the normalization layers in Tensorflow. Most online articles are talking about the mathematical definitio...